In modern web development, the challenge isn’t just writing code; it’s about how you build, deploy, and manage that code in production. Imagine you’ve built a user management API that’s gaining traction. As your user base grows, you face three critical issues:
- Increased traffic that risks server overload.
- Some clients are making excessive API requests.
- The looming complexity of manual deployments that are both error-prone and time-consuming.
Ready to take on these challenges? I am going to guide you through a hands-on, DIY DevOps solution. While there are many specialized tools on the market, there’s immense value in understanding and building a solution from more fundamental components. Our stack will include Flask for the API, Redis for rate-limiting, Docker for containerization, Kubernetes for orchestration and scaling, and Jenkins for continuous integration and deployment (CI/CD). This DIY approach solves the immediate problems and offers profound insights into the entire development lifecycle, making you a more well-rounded and skilled technical professional.
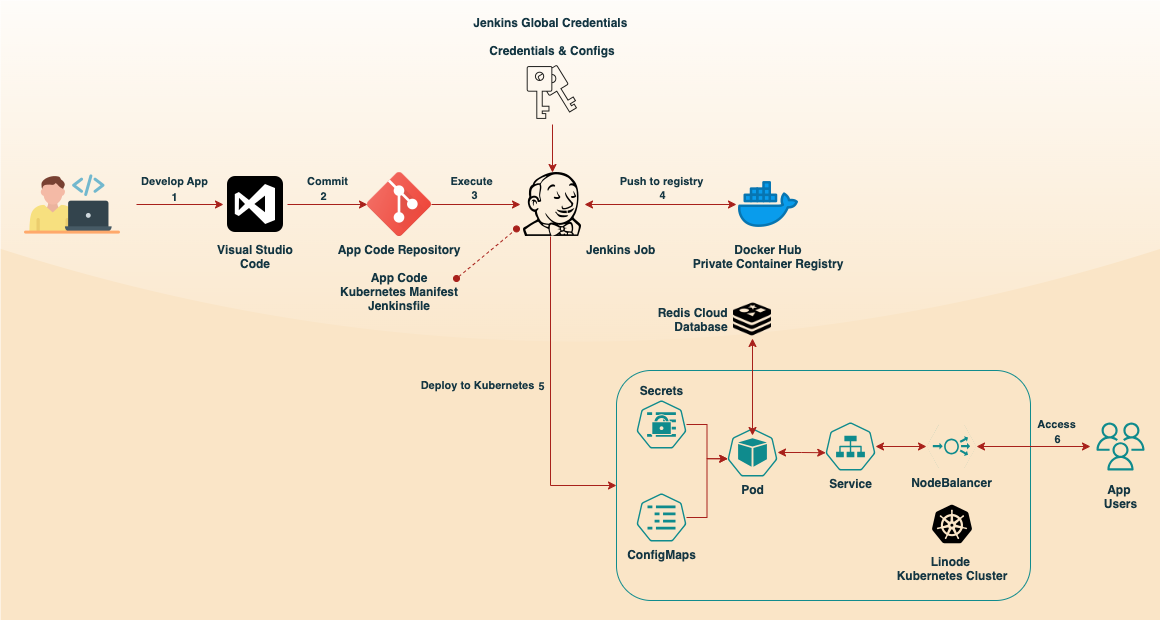
Setting Up Linode Kubernetes Service
To deploy our application on Kubernetes, we utilized Linode’s Kubernetes service. Linode offers a user-friendly platform with a $100 credit for new users, making it an ideal environment for testing and exploring Kubernetes capabilities. After creating an account and setting up a Kubernetes cluster through the Linode dashboard, the crucial step is downloading the kubeconfig file from the Linode interface. This file is necessary to run kubectl via Jenkins job, enabling you to manage your cluster directly.
Setting Up Redis Cloud Database
We’ll use Redis, a fast in-memory database, to start our rate-limiting setup. We are using the free Redis Cloud DB provided by Redis Labs for simplicity and cost-effectiveness. This service offers a free tier that is sufficient for our needs.
Follow this YouTube tutorial to set up your free Redis Cloud database.
Once your Redis instance is up and running, it’s crucial to jot down the connection details (host, port, and password). These will be essential for the next steps, so make sure to have them at hand.
Setting Up the Flask App
Let’s dive into the heart of our API, which was built with Flask and fortified with Redis for rate-limiting. In app.py, we define a RedisService class as the linchpin of our rate-limiting strategy. We extract the client’s IP address for each incoming request, cleverly handling cases where the client might be behind a proxy. This IP becomes the key in our Redis store and is associated with a counter that increments each request. Suppose a client exceeds our defined limit(in this case, five requests per minute). They receive a 429 “Too Many Requests” error. The beauty of using Redis lies in its speed and its built-in key expiration feature. After 60 seconds, the counter resets, giving each client a fresh start. This simple yet effective mechanism ensures fair API usage without the need for complex algorithms or third-party services.
Here is the complete code for the Flask application:
import logging
from flask import Flask, request, jsonify
from redis import Redis, ConnectionError
import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
app = Flask(__name__)
FLASK_PORT = int(os.getenv('FLASK_PORT', 5000))
RATE_LIMIT = int(os.getenv('RATE_LIMIT', 5))
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', 19435))
REDIS_PASSWORD = os.getenv('REDIS_PASSWORD', 'xxxx')
class RedisService:
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
self.redis_client = Redis(host=host, port=port, password=password)
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.INFO)
def get_client_ip(self):
self.logger.info(f"Request Headers: {request.headers}")
if request.headers.getlist("X-Forwarded-For"):
ip_address = request.headers.getlist("X-Forwarded-For")[0]
else:
ip_address = request.remote_addr
self.logger.info(f"Client IP: {ip_address}")
return ip_address
def check_rate_limit(self):
ip_address = self.get_client_ip()
key = f"rate_limit:{ip_address}"
try:
current_count = self.redis_client.get(key)
if current_count and int(current_count) >= RATE_LIMIT:
self.logger.info(f"Rate limit exceeded for IP: {ip_address}")
return True # Rate limit exceeded
# Initialize count to 0 if it doesn't exist yet
if current_count is None:
self.redis_client.setex(key, 60, 0)
# Increment request count
self.redis_client.incr(key)
# If count is now RATE_LIMIT, set expiry time to ensure it expires after 60 seconds
if int(self.redis_client.get(key)) == RATE_LIMIT:
self.redis_client.expire(key, 60)
except ConnectionError as e:
self.logger.error(f"Redis connection error: {e}")
return False # In case of error, do not block the request
return False # Rate limit not exceeded
redis_service = RedisService()
@app.before_request
def before_request():
if redis_service.check_rate_limit():
return jsonify({"error": "Rate limit exceeded"}), 429
@app.route("/api/users/sample")
def get_sample_users():
sample_users = [
{"id": 1, "name": "test1", "email": "test1@sample.com"},
{"id": 2, "name": "test2", "email": "test2@sample.com"},
]
return jsonify(sample_users)
def main() -> None:
logging.basicConfig(level=logging.INFO)
app.run(host="0.0.0.0", port=FLASK_PORT, debug=False)
if __name__ == "__main__":
main()
Environment Variables (app/.env)
The .env file contains the environment variables required by the Flask application:
FLASK_ENV=production
FLASK_PORT=5000
REDIS_HOST=xxxx.redns.redis-cloud.com
REDIS_PORT=19435
REDIS_PASSWORD=xxxx
RATE_LIMIT=5
Dependencies (app/requirements.txt)
Here are the dependencies listed in requirements.txt:
Flask==2.2.5
Werkzeug==3.0.3
redis==4.6.0
python-dotenv==0.21.0
Dockerizing the Flask App
Our API isn’t just about rate-limiting; it also serves data. The /api/users/sample endpoint returns a list of sample users. In a real-world scenario, this could be fetching data from a database, aggregating analytics, or any resource-intensive task that necessitates rate-limiting. Applying the rate-limit check via the before_request decorator ensures that every endpoint in our Flask app is protected, providing a blanket of security and performance optimization.
With our API logic solidified, the next step is containerization with Docker. Our Dockerfile is a testament to modern DevOps practices. We use a multi-stage build process, starting with a python:3.9-slim image. We install only the necessary dependencies in the build stage, keeping our image lean and reducing potential security vulnerabilities. The final stage copies just the essentials: our Python packages and the application code. This results in a smaller, more secure image that can be consistently deployed across various environments, from a developer’s laptop to a production server. Containerization isn’t just a buzzword; it’s a fundamental shift in how we package and deploy applications, ensuring that “it works on my machine” becomes “it works everywhere.”
Here is the Dockerfile for our Flask application:
# Use the official Python image based on Alpine Linux as the base image
FROM python:3.9-alpine AS build-stage
# Set environment variables
ENV PYTHONUNBUFFERED=1
# Install build dependencies
RUN apk add --no-cache build-base libffi-dev
# Set the working directory
WORKDIR /app
# Copy the requirements.txt file and install the necessary dependencies
COPY app/requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY app /app
# Use a minimal Python image as the base for the final image
FROM python:3.9-alpine
# Set environment variables
ENV FLASK_ENV=production
# Set the working directory
WORKDIR /app
# Copy the installed dependencies from the build stage
COPY --from=build-stage /usr/local/lib/python3.9/site-packages /usr/local/lib/python3.9/site-packages
COPY --from=build-stage /usr/local/bin /usr/local/bin
# Copy the application code
COPY app /app
# Expose the port that the Flask app runs on
EXPOSE 5000
# Run the application
CMD ["python", "app.py"]
Kubernetes Manifest
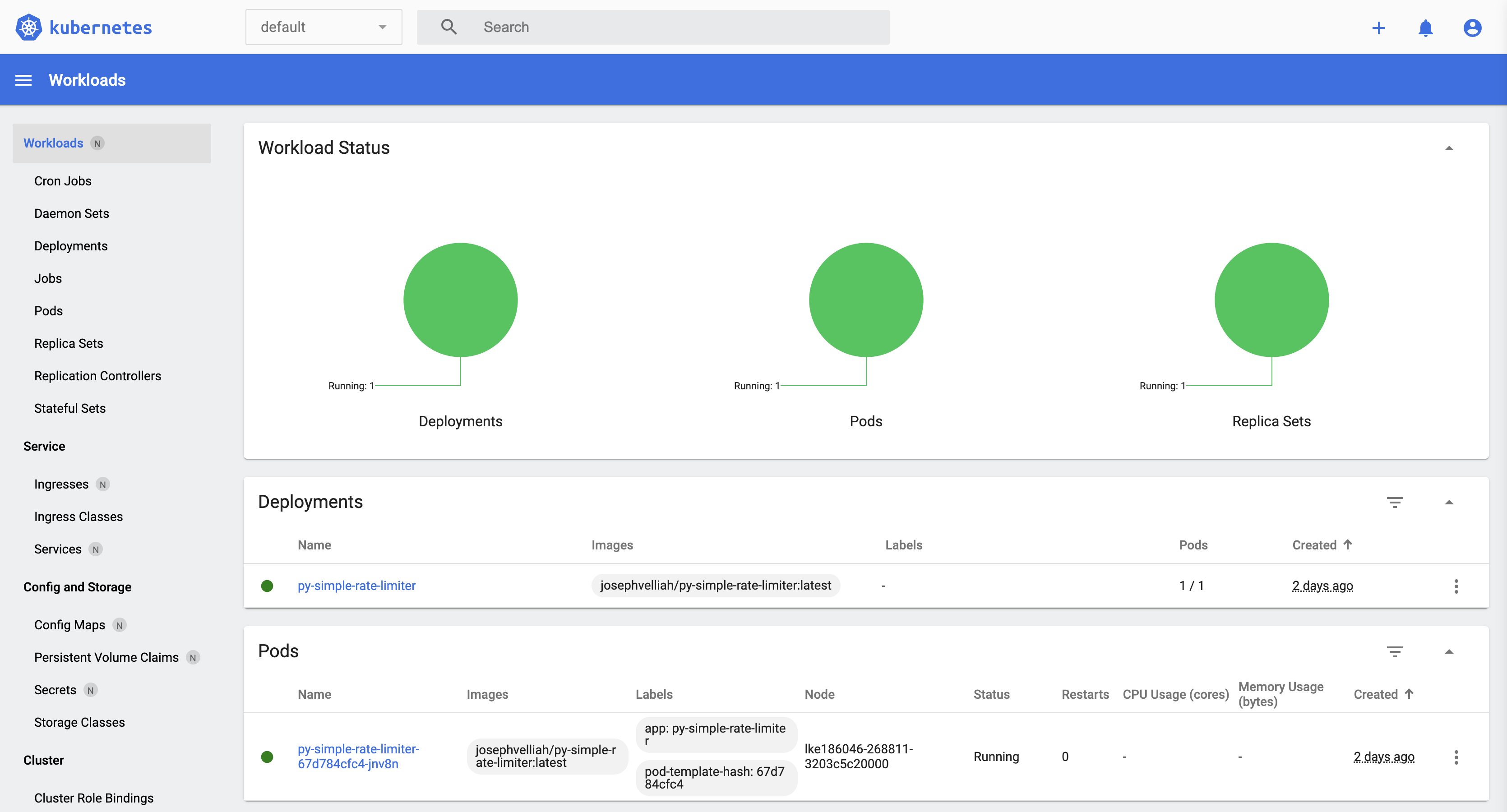
Now, imagine our API becomes a runaway success. We’re talking thousands of requests per second. This is where Kubernetes, our container orchestration platform, shines. At the same time, we have yet to delve into the specifics of k8s/manifest.yaml, our Jenkins pipeline gives us clues about its contents. It likely defines a deployment for our Flask app, allowing Kubernetes to manage multiple instances (pods) of our application. As traffic increases, Kubernetes can automatically spin up more pods to handle the load, and when traffic dips, it scales back down, optimizing resource use. But Kubernetes does more than just scale; it also makes our app resilient. If a pod crashes, Kubernetes immediately replaces it, ensuring high availability.
Moreover, it simplifies the management of configurations and secrets. Instead of hardcoding sensitive data like our Redis password, we use Kubernetes secrets, and for tunable parameters like rate limits, we use ConfigMaps. This separation of code, configuration, and secrets is a DevOps best practice that enhances security and flexibility.
Here is the complete Kubernetes manifest file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: py-simple-rate-limiter
spec:
replicas: 1
selector:
matchLabels:
app: py-simple-rate-limiter
template:
metadata:
labels:
app: py-simple-rate-limiter
spec:
containers:
- name: py-simple-rate-limiter
image: ${DOCKER_HUB_REPO}:latest
ports:
- containerPort: 5000
env:
- name: FLASK_ENV
value: "production"
- name: FLASK_PORT
value: "5000"
- name: REDIS_HOST
valueFrom:
configMapKeyRef:
name: redis-host-url
key: redis-host
- name: REDIS_PORT
value: "19435"
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis-password-secret
key: redis-password
- name: RATE_LIMIT
value: "5"
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: "500m"
imagePullSecrets:
- name: regcred
---
apiVersion: v1
kind: Service
metadata:
name: py-simple-rate-limiter-service
spec:
selector:
app: py-simple-rate-limiter
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
Setting Up Jenkins Pipeline
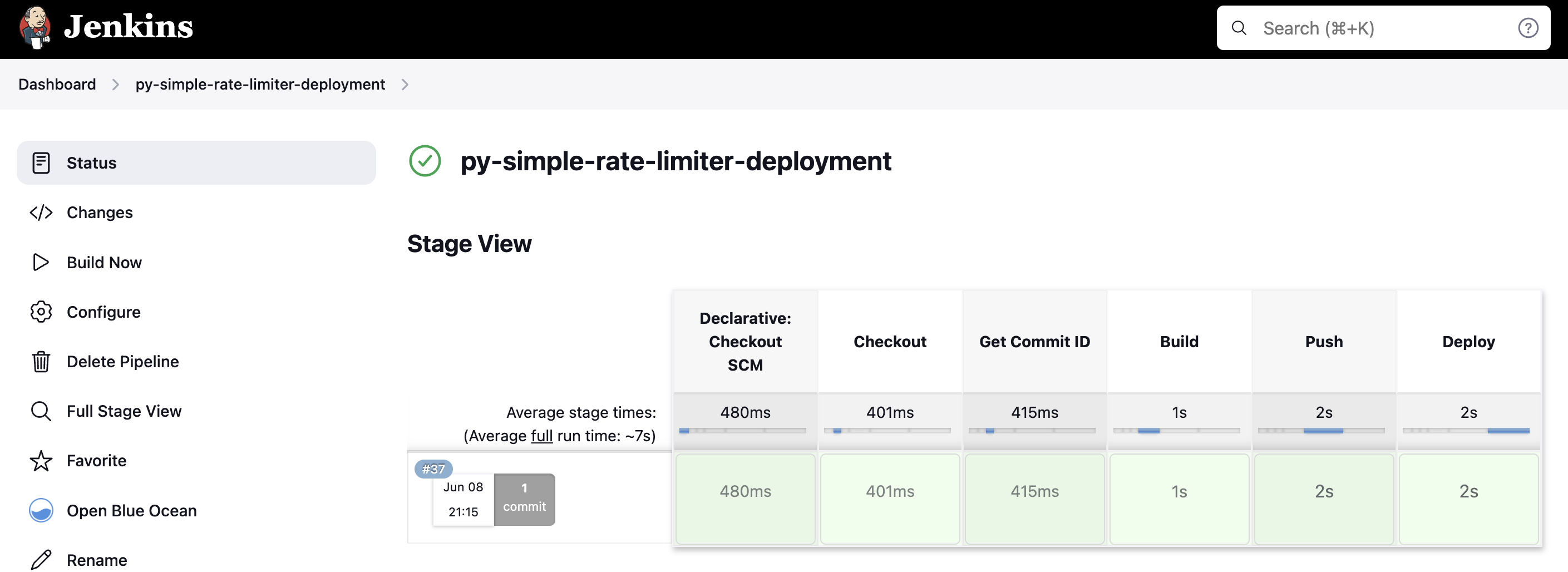
The final piece of our DevOps puzzle is continuous integration and deployment (CI/CD), orchestrated by Jenkins. Our Jenkinsfile is an automation blueprint. Every time we push code to our repository, Jenkins springs into action. It starts by checking out our code and capturing the current commit ID, providing traceability for every build. Next, it builds our Docker image, leveraging the multi-stage Dockerfile we crafted earlier. But the building is just the start; Jenkins then pushes this image to Docker Hub, our container registry. This step is crucial because it makes our latest code accessible to any environment that can pull from Docker Hub.
The real magic happens in the deployment stage. Jenkins doesn’t just build and forget; it takes responsibility for updating our live application. Using the withKubeConfig and withCredentials wrappers, Jenkins securely accesses our Kubernetes cluster and Docker Hub. It creates a docker-registry secret in Kubernetes, allowing our cluster to pull the private Docker image. Then, it sets up a ConfigMap and a secret for our Redis connection details.
Finally, the following one line updates our Kubernetes deployment with the latest Docker image. Our new code will be live, serve requests, and be protected by our rate limiter in minutes.
envsubst < k8s/manifest.yaml | kubectl apply -f -
Here is the Jenkinsfile:
pipeline {
agent any
environment {
DOCKER_HUB_CREDENTIALS_ID = 'docker-hub-credentials-id'
DOCKER_HUB_REPO = credentials('docker-hub-repo-id')
KUBE_CONFIG_CREDENTIALS_ID = 'kube-config-credentials-id'
KUBE_CONTEXT = credentials('kube-context-id')
REDIS_HOST = credentials('redis-host-credentials-id')
REDIS_PASSWORD = credentials('redis-password-credentials-id')
DOCKER_BUILDKIT = '1'
}
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Get Commit ID') {
steps {
script {
COMMIT_ID = sh(script: 'git rev-parse --short HEAD', returnStdout: true).trim()
echo "Building Docker image for commit ID: ${COMMIT_ID}"
}
}
}
stage('Build') {
steps {
script {
docker.build("${DOCKER_HUB_REPO}:latest", ".")
}
}
}
stage('Push') {
steps {
script {
docker.withRegistry('https://index.docker.io/v1/', "${DOCKER_HUB_CREDENTIALS_ID}") {
docker.image("${DOCKER_HUB_REPO}:latest").push()
}
}
}
}
stage('Deploy') {
steps {
withKubeConfig([credentialsId: "${KUBE_CONFIG_CREDENTIALS_ID}", contextName: "${KUBE_CONTEXT}"]) {
withCredentials([usernamePassword(credentialsId: "${DOCKER_HUB_CREDENTIALS_ID}", usernameVariable: 'DOCKER_USERNAME', passwordVariable: 'DOCKER_PASSWORD')]) {
script {
// Create the Kubernetes secret for Docker registry
sh """
kubectl create secret docker-registry regcred \
--docker-server=https://index.docker.io/v1/ \
--docker-username="${DOCKER_USERNAME}" \
--docker-password="${DOCKER_PASSWORD}" \
--dry-run=client -o yaml | kubectl apply -f -
"""
// Create the configmap and secret for Redis
sh """
kubectl create configmap redis-host-url --from-literal=redis-host="${REDIS_HOST}" --dry-run=client -o yaml | kubectl apply -f -
kubectl create secret generic redis-password-secret --from-literal=redis-password="${REDIS_PASSWORD}" --dry-run=client -o yaml | kubectl apply -f -
"""
// Substitute the Docker image in the Kubernetes manifest and apply it
sh """
export DOCKER_HUB_REPO=${DOCKER_HUB_REPO}
envsubst < k8s/manifest.yaml | kubectl apply -f -
"""
}
}
}
}
}
}
}
Deploying the Application
Before running your Jenkins job to deploy the application, ensure all necessary credentials are set in the environment section of the Jenkinsfile. This includes Redis connection details, Docker Hub repository credentials, and Kubernetes context configurations, which are crucial for the pipeline to access your Docker images and manage the Kubernetes cluster. Once these credentials are correctly configured, initiate the Jenkins pipeline. This process will build and deploy your Flask API integrated with Redis rate-limiting, utilizing Docker for containerization and Kubernetes for orchestration. Successful execution of this pipeline ensures your application is live and capable of scaling efficiently while managing incoming traffic through rate limiting.
Configuring Linode NodeBalancer
One crucial aspect of our setup is ensuring that the client IP addresses are forwarded correctly to our application. By default, when using the TCP protocol, the NodeBalancer does not forward the client IP address, which is essential for our rate-limiting logic.
We need to change the NodeBalancer protocol from TCP to HTTP to solve this. Here’s how to do it:
- Log into your Linode account: Access your Linode account dashboard.
- Navigate to the NodeBalancer section. Find and select the NodeBalancer you are using for your application.
- Edit the Configuration:
- Locate the NodeBalancer configuration settings.
- Change the protocol from TCP to HTTP for the frontend port. This ensures that the X-Forwarded-For header containing the client’s IP address is correctly set and forwarded to your application.
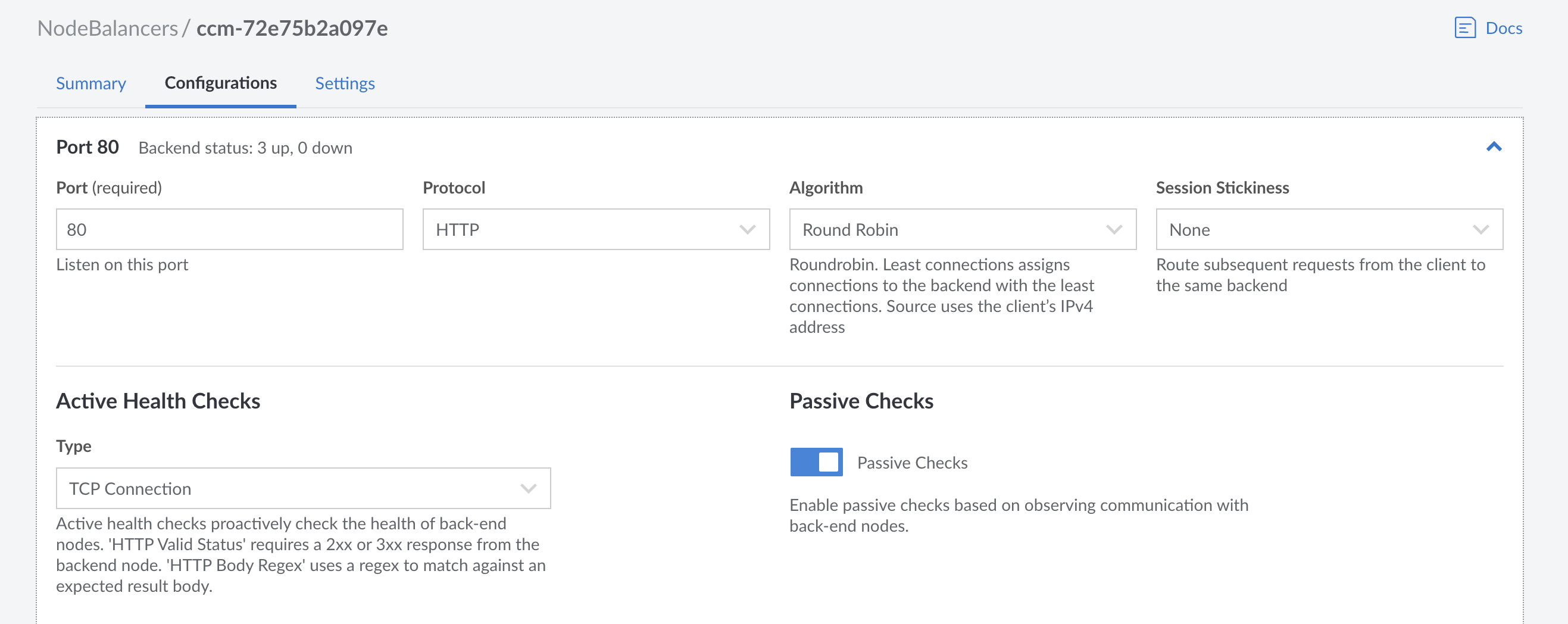
Changing the protocol to HTTP enables proper client IP forwarding, which is crucial for accurate rate-limiting based on the client’s IP address.
Testing the Setup
With everything set up, it’s time to test the deployment and ensure everything works as expected.
Access the Service: Find the external IP address of your Kubernetes service. You can get this by running:
kubectl get svc py-simple-rate-limiter-service
Test the API: Use postman or any other HTTP client to test the /api/users/sample endpoint:
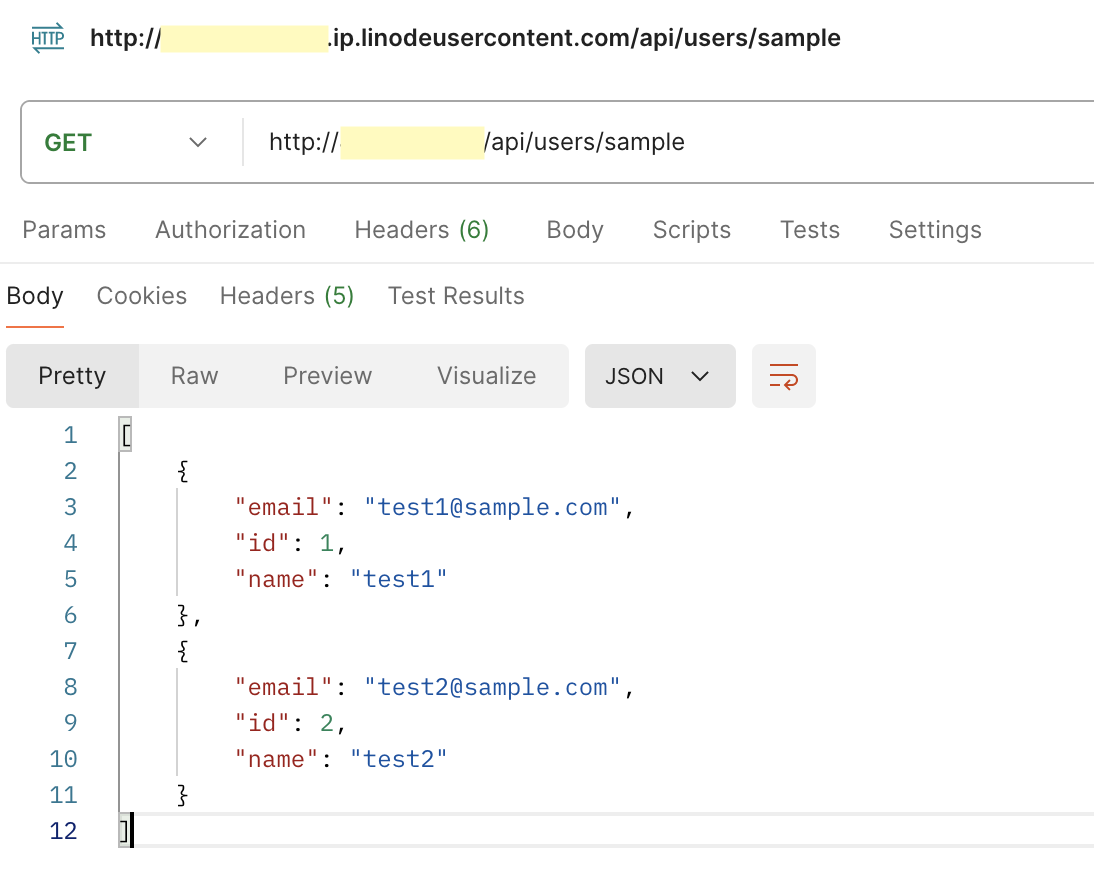
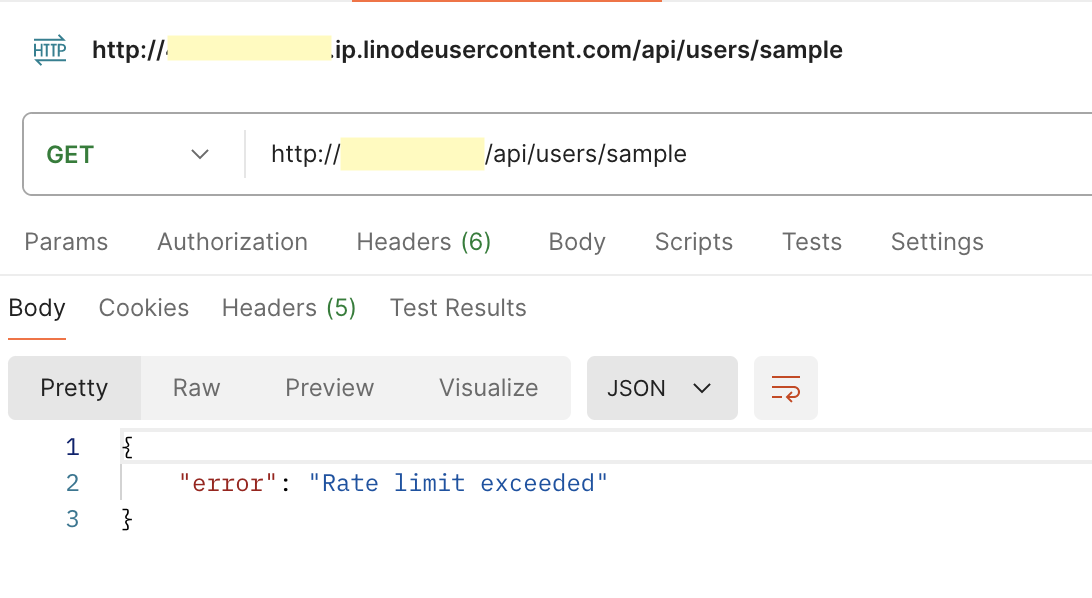
Simulate Requests
Send multiple requests to see if the rate-limiting works. After five requests in a minute (based on our rate limit), you should receive a 429 “Too Many Requests” error.
Wrap-Up
Following these steps, you set up a rate-limited API using Flask, Redis, Docker, Kubernetes, and Jenkins. This setup addresses immediate challenges like traffic management and API abuse and implements modern DevOps practices that ensure scalability, resilience, and automated deployments.
Let’s recap the journey:
- Flask and Redis: We built the core API with rate limiting.
- Docker: Containerized the application for consistent deployment.
- Kubernetes: Orchestrated and scaled the application.
- Jenkins: Automated the CI/CD pipeline.
- Linode NodeBalancer: Configured for proper client IP forwarding.
You’ve created a robust, scalable, automated solution by understanding and integrating these components. This approach solves current problems and lays a solid foundation for future growth and complexity. This project demonstrates how a thoughtful combination of different tools and practices can lead to a powerful, flexible, and maintainable infrastructure. To achieve greater success, keep exploring, learning, and applying these principles to your future projects.