As an Automation Engineer with a passion for Cloud Computing, DevOps, and Distributed Systems, I wanted to create an application that could automatically extract content from a resume PDF and generate answers to user queries based on the extracted data. To achieve this, I used Python Flask, PyPDF2, and the OpenAI API.
If you would like to look at the source files for this post, you can find them in this repository.
How It Works
Data Extraction: The first step was to extract text from the resume PDF. To do this, I utilized PyPDF2, a Python library that allows us to read and manipulate PDF files. I created a function extract_text_from_pdf(pdf_file) that takes the path to the resume PDF as input and returns the extracted text.
Knowledge Base: To store the extracted resume data, I initialized an empty knowledge base, which is essentially a list of dictionaries. Each dictionary contains the extracted text from a specific resume.
OpenAI Integration: I integrated the OpenAI GPT-3.5 model to generate answers to user queries based on the resume content. Before running the application, I set up the OpenAI API key as an environment variable using the python-dotenv library. This ensures the API key is kept secure and not exposed in the code.
Flask App: I developed a Flask web application with two endpoints: /add_resume and /query. The /add_resume endpoint allows users to upload their resume PDF, and the content is extracted and added to the knowledge base. The /query endpoint handles user queries and responds with relevant answers.
ChatGPT Response: To generate answers, I used a function called generate_chatgpt_response(prompt). This function utilizes the OpenAI API to interact with the GPT-3.5 model and returns a response based on the user query and the latest resume content from the knowledge base.
Testing the App
To test the app locally, I set up a virtual environment and installed the required packages listed in the requirements.txt file. I also created a .env file to store the OpenAI API key as an environment variable.
I ran the Flask app using the python3 app.py command and accessed it through the browser. I used curl commands to test the /add_resume and /query API calls.
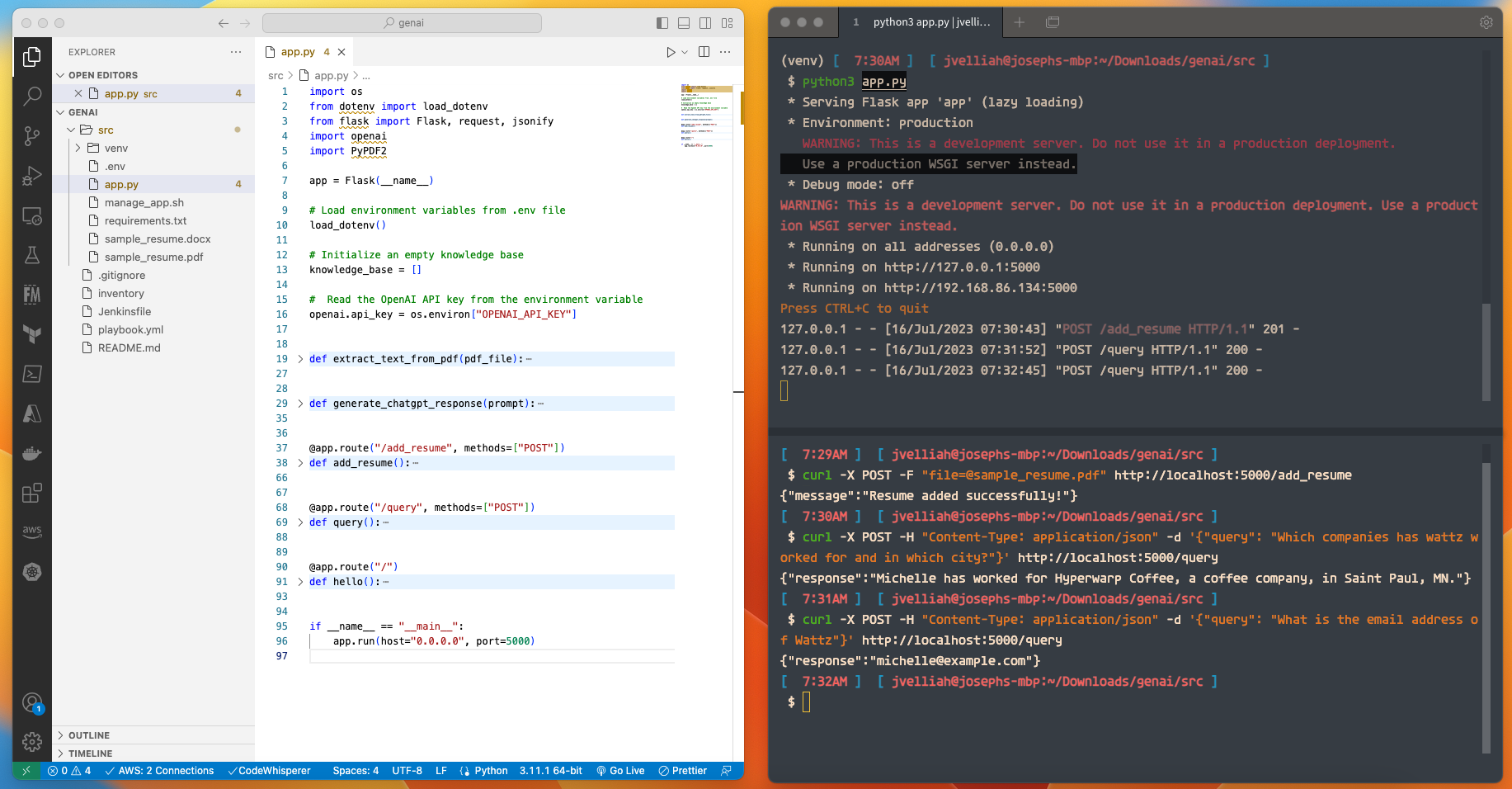
For /add_resume, I prepared a sample resume in PDF format and used the curl command to upload it to the app. The extracted content was added to the knowledge base, and I received a success message.
For /query, I tested different user queries and received answers generated by the ChatGPT model based on the resume content.
Wrap-Up
Overall, by combining the power of Python Flask, PyPDF2, and the OpenAI GPT-3.5 model, I created a dynamic application that can extract content from resume PDFs and provide answers to user queries based on the extracted information. This application has the potential to save time and effort in resume analysis and provide valuable insights to users seeking relevant information from resumes.
We can harness the power of AI-Powered Data Parsing for Smart Answers in a variety of use cases. Here are some examples:
Top 2 Scenarios
Knowledge Base Chatbot: This scenario involves building a chatbot that uses a knowledge base of articles, FAQs, or documents to answer user questions on a specific topic or domain. Users can interact with the chatbot by asking questions, and the bot will generate relevant responses based on the content in the knowledge base. This can be valuable for customer support, educational platforms, or any domain where a well-structured knowledge base is available.
Legal Document Analysis: In this scenario, the application involves extracting key information from legal documents, contracts, or agreements. Users can ask specific questions about the document, and the system will generate answers based on the extracted content. This can be useful for legal professionals, researchers, or anyone dealing with legal documents.
Fine-Tuning the Code for Better Responses:
If the ChatGPT model doesn’t provide proper or accurate responses, there are several ways to improve the system:
-
Larger Knowledge Base: Expand the knowledge base with more diverse and relevant documents. A broader range of data can help the model generate more accurate responses.
-
Model Selection: Experiment with different models provided by OpenAI’s GPT, like gpt-3.5-turbo, to see which one performs better for your specific use case.
-
Prompt Engineering: Adjust the prompts used to interact with the ChatGPT model. By crafting more specific and informative prompts, you can guide the model to generate better responses.
-
Feedback Loop: Implement a feedback loop where users can rate the quality of responses. This data can be used to fine-tune the model and improve future interactions.
-
Post-Processing: Apply post-processing techniques to the generated responses to ensure correctness and consistency.
-
Fine-Tuning the Model: If you have access to a fine-tuned version of the GPT model, you can train it on your specific domain or dataset to obtain more accurate and domain-specific responses.
-
Integrate Intent Recognition: Implement intent recognition techniques to better understand user queries and route them to specific sections of the knowledge base.
-
Handling Ambiguity: Account for ambiguous queries by providing clarifying questions to users or using context to disambiguate the questions.
-
Error Analysis: Perform error analysis to identify common failure cases and find patterns that need improvement.
Remember that language models like GPT-3.5 are very powerful, but their performance can vary based on the quality and size of the knowledge base, as well as the specificity of the prompts and user interactions. Fine-tuning and iterative improvements are crucial to enhancing the system’s overall effectiveness and user experience.